
はじめに
Power Automate Desktopのアクションのみで重複削除の処理を検証していきます。
今回は以下の条件を実現できるかの検証をしていきます。
・すべての列の値が同じデータがあった場合に、重複分のデータを削除する
・重複している場合は、行インデックスが一番低い数字の行を残し、他のデータを削除する
使用するデータ
今回用意するサンプルデータ
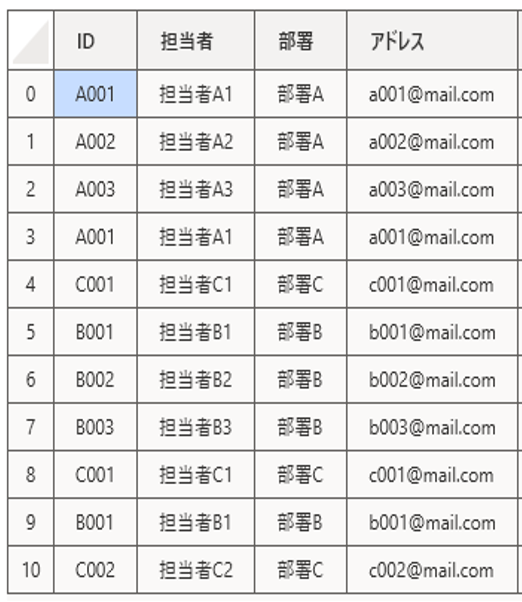
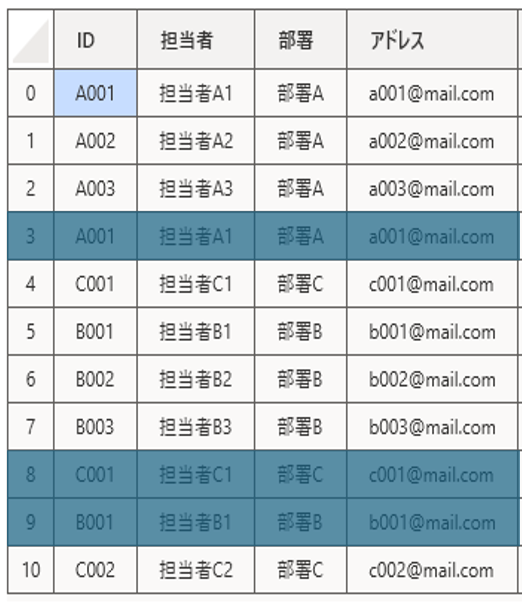
削除対象になるのはネイビーで塗りつぶされているデータです。
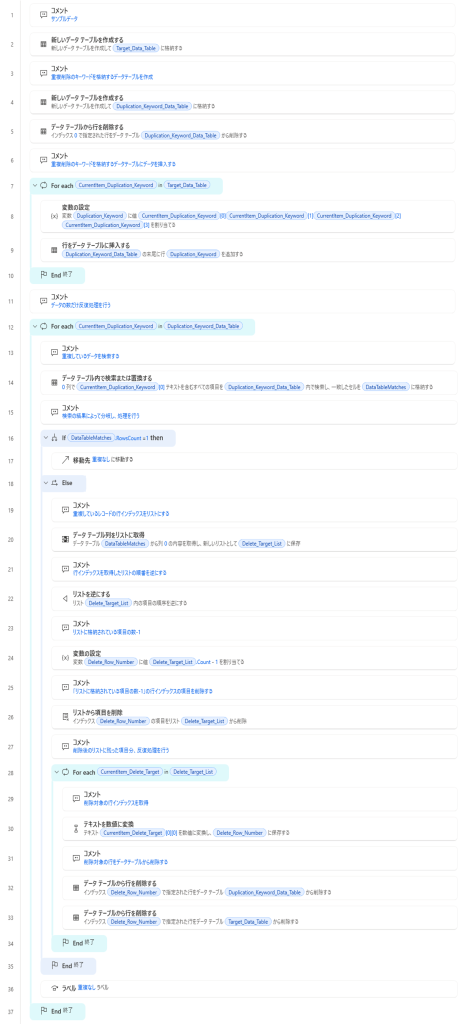
フローの完成系
先にフローの完成系を載せておきます。その後に設定手順を説明していきます。
設定手順
1. 重複削除をするデータの作成
※今回はサンプルデータとしてPowerAutomateないでデータテーブルを作成していますが、Excelなどのファイルから読み取ってデータテーブルにすることが多いと思います。

2. 重複削除のキーワードを格納するデータテーブルを作成
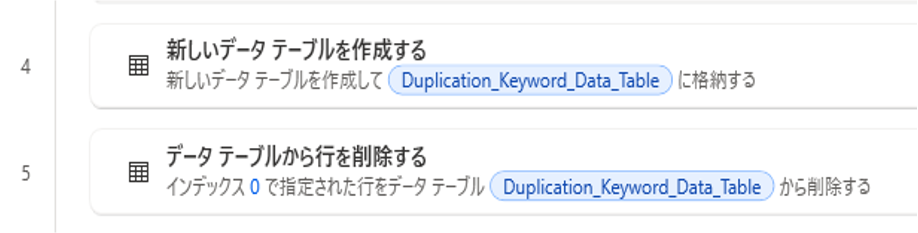
インデックス0の行を削除

3. 重複削除のキーワードを格納するデータテーブルにデータを挿入する
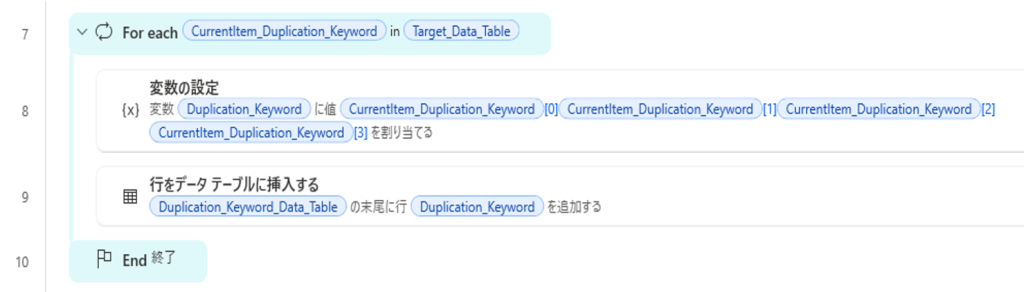
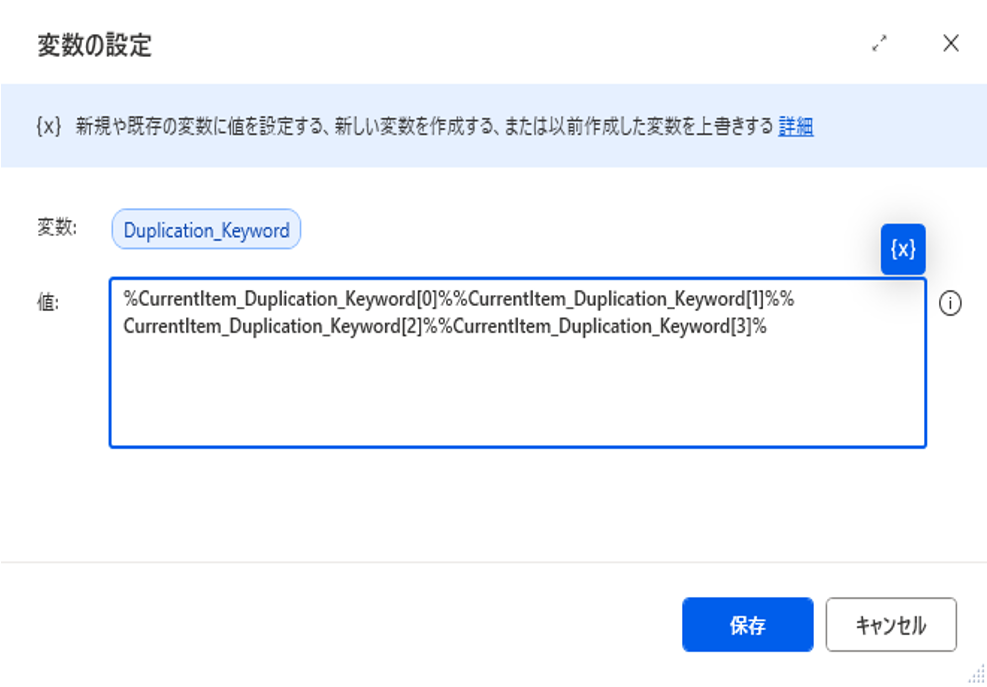
重複確認の対象列の値を文字列結合した変数(Duplication_Keyword)を作成する
%CurrentItem_Duplication_Keyword[0]%%CurrentItem_Duplication_Keyword[1]%%CurrentItem_Duplication_Keyword[2]%%CurrentItem_Duplication_Keyword[3]%
文字列結合した変数(Duplication_Keyword)の値をデータテーブル(Duplication_Keyword_Data_Table)に挿入する

4. データの数だけ反復処理を行う

5. 重複しているデータを検索する

検索対象:重複削除のキーワードが格納されたインデックスが0の列
検索するテキスト:重複削除のキーワード
6. 検索の結果によって分岐し、処理を行う
重複がなかった場合
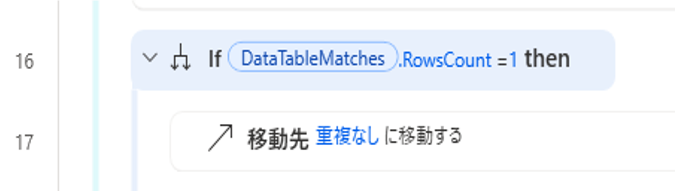
反復処理の最後のラベルにとばす

重複がなかった場合は検索したテキストに一致するデータ数は1になるため、以下の条件式で設定
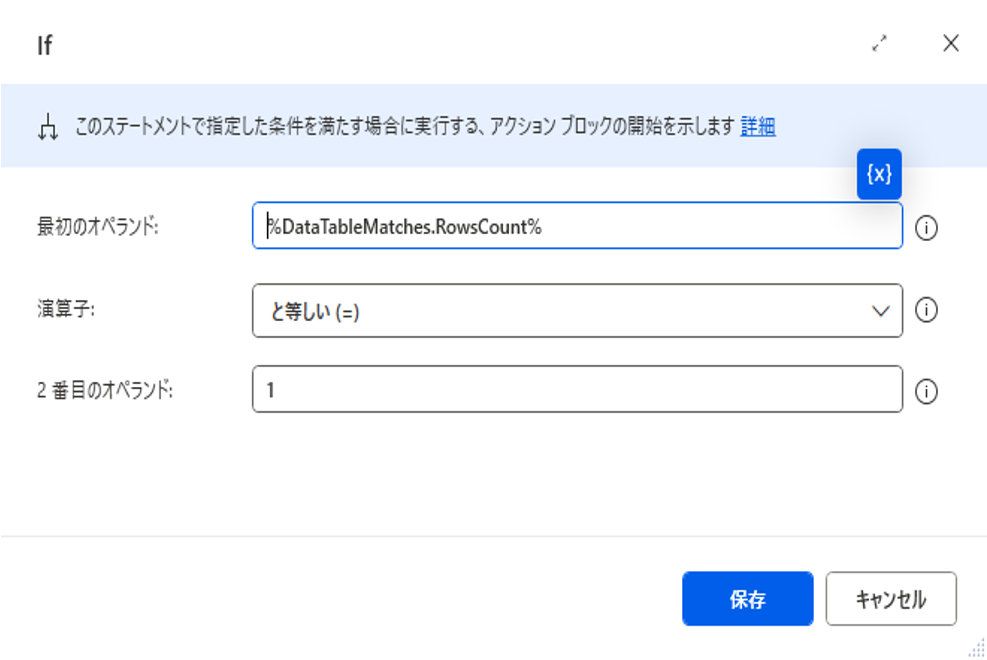
重複があった場合
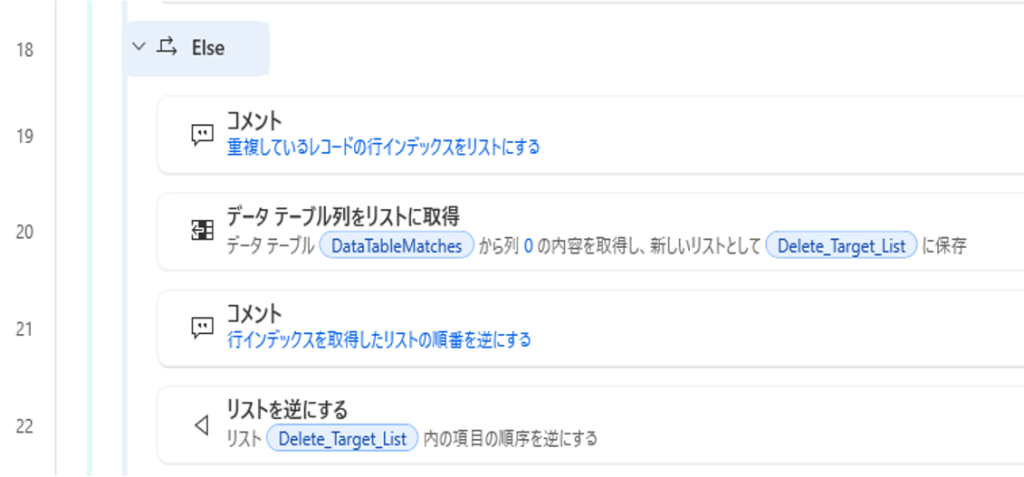
重複しているデータの行インデックスをリストにし、リストを逆にする。
リストを逆にするのは、行インデックスの数字が大きい方から削除していかないと、削除対象のデータがずれるため。
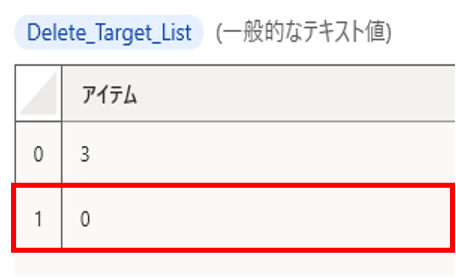
IDがA001で重複しているデータの場合は以下のような流れでリストが作成され、順番が逆になる

「リストに格納されている項目の数-1」の行インデックスの項目を削除
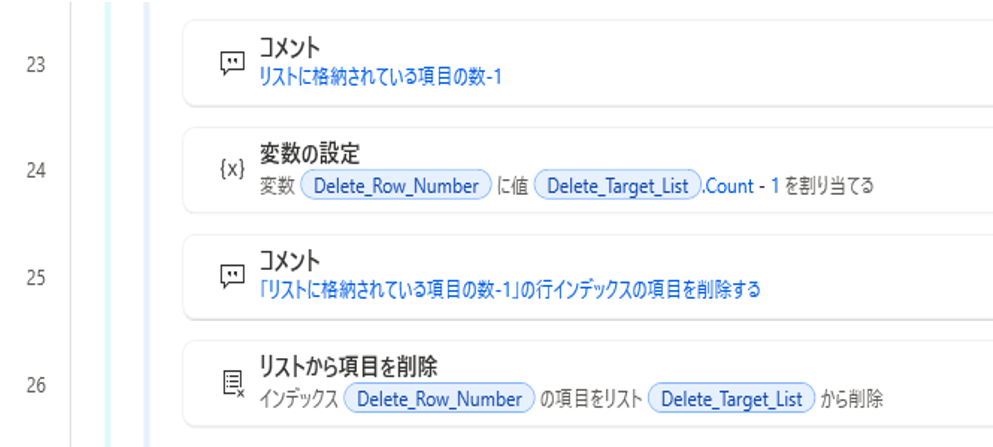
冒頭に記載したように、重複があった場合は行インデックスが一番小さい値のデータを残すため、該当の行インデックスをリストから削除する。
行インデックスは0からカウントするため、「リストの数-1」すると、リストの最後の行インデックスと同じ数字になる。
削除後のリストに残った項目分、反復処理を行う

削除対象の行インデックスを数値で取得し、削除対象の行をデータテーブルから削除する
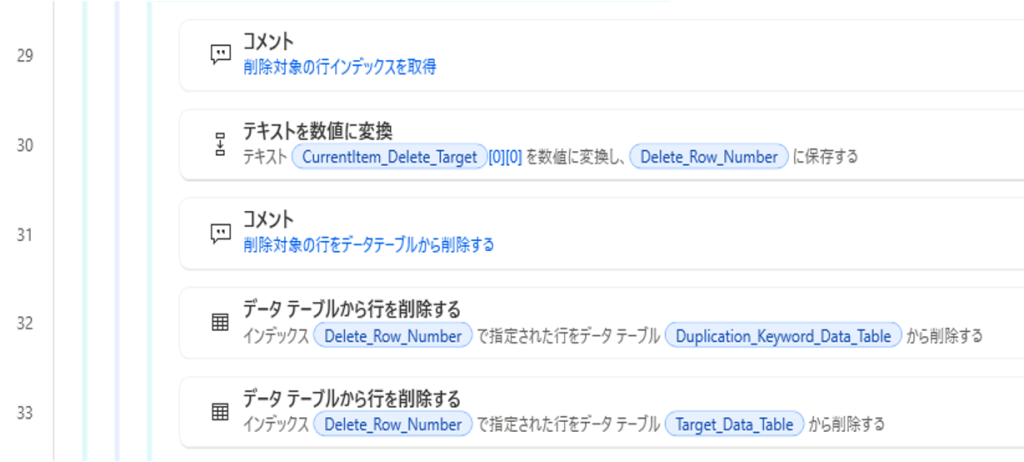
7. 反復の終了

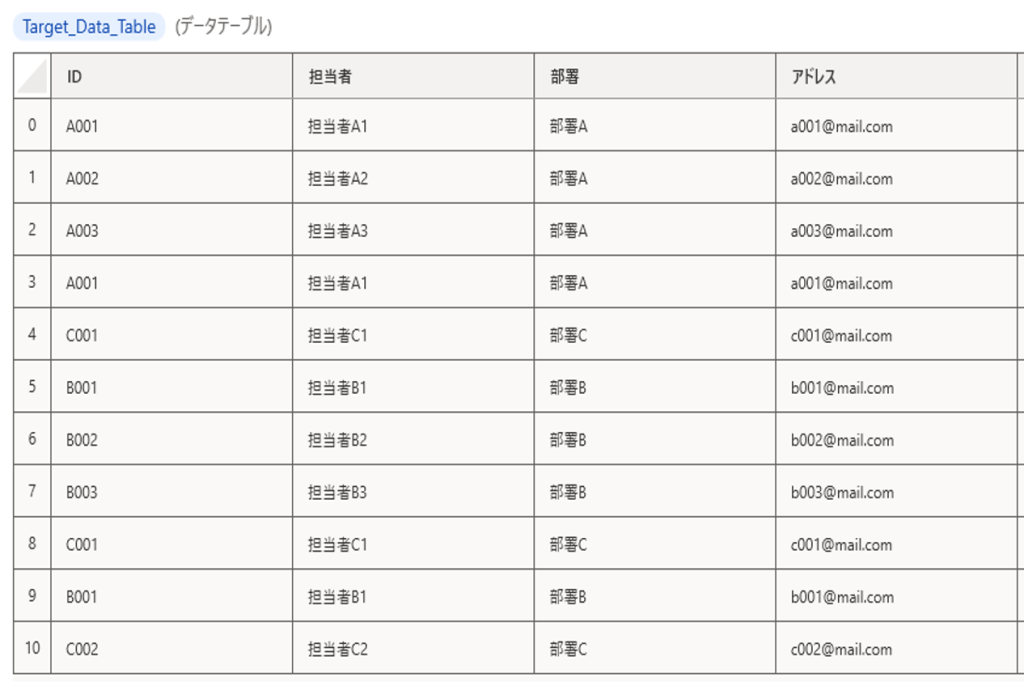
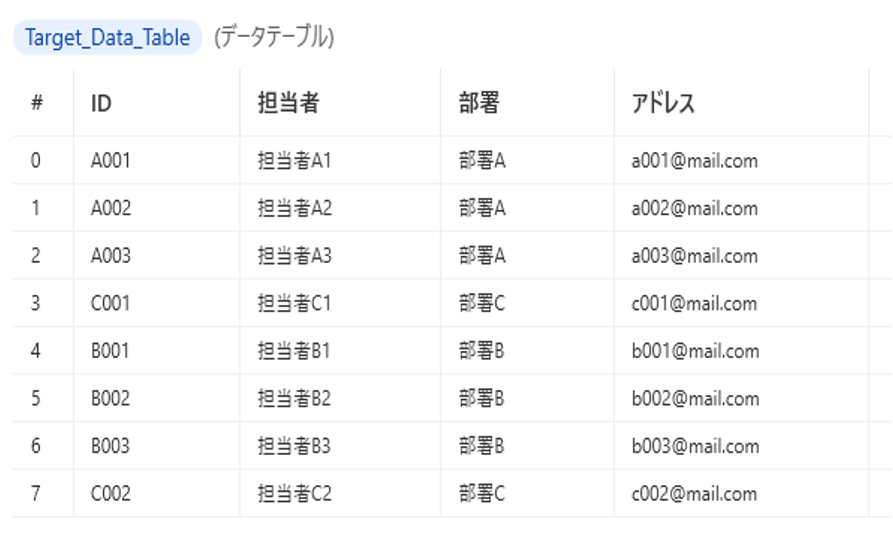
結果
重複処理後のデータテーブル
おわりに
Excelの重複削除機能を使わずに、PowerAutomate内で重複削除の処理が完結できました。
ただ、対象のデータ量が多いと、かなり時間がかかります。
状況に応じてExcelの重複削除機能を使用することや、Pythonで重複処理をするなど使い分けられるとよいと思います。

