
本記事の内容
PythonのPandas、Numpyを使用して特定の文字を含むレコード数を出力します。
前提
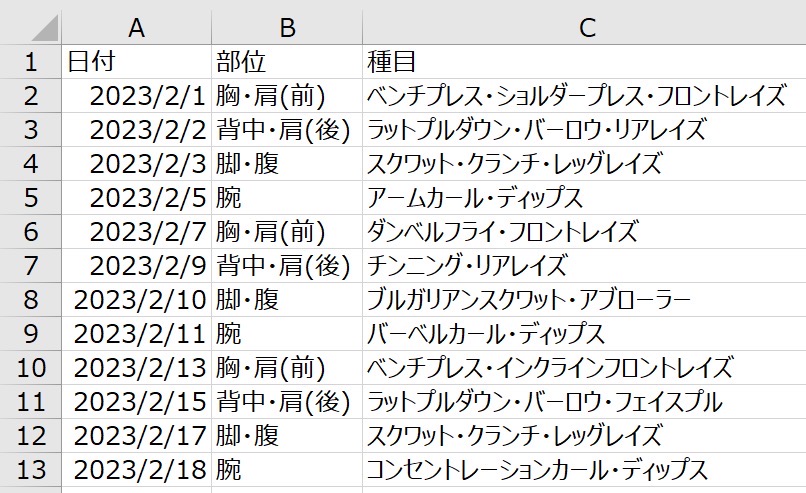
以下のようなcsvデータを使用して本記事の内容を進めていきます。
ファイル名:sample.csv
Pandas、Numpyのライブラリを読み込む
毎回pandas、numpyで呼び出すのではなく、一般的にpd、npとして呼び出します。
import pandas as pd
import numpy as npcsvファイルを読み込む
df = pd.read_csv('sample.csv', encoding='UTF-8')
df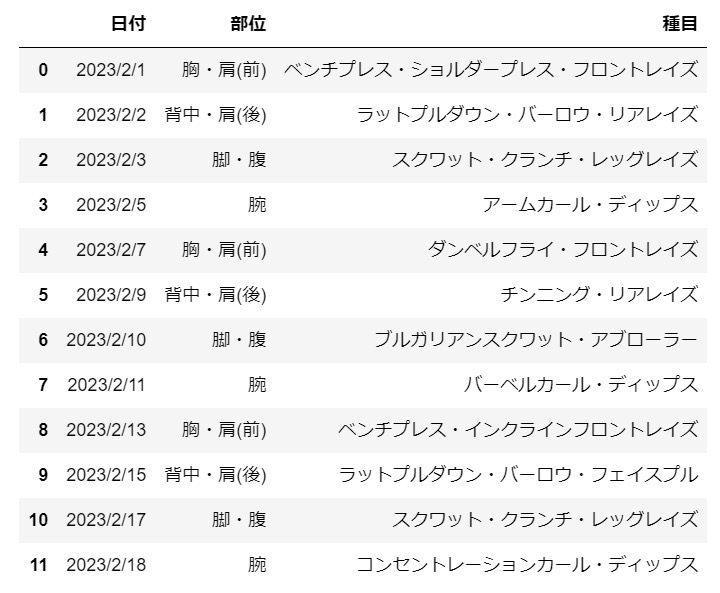
特定のワードを含むか否かを判断する列を追加する
今回は種目列にベンチプレスという文字を含むか否かを判断します。
含む場合は1、含まない場合は0となるように設定します。
df['keyword'] = np.where(df['種目'].str.contains('ベンチプレス'), 1, 0)
df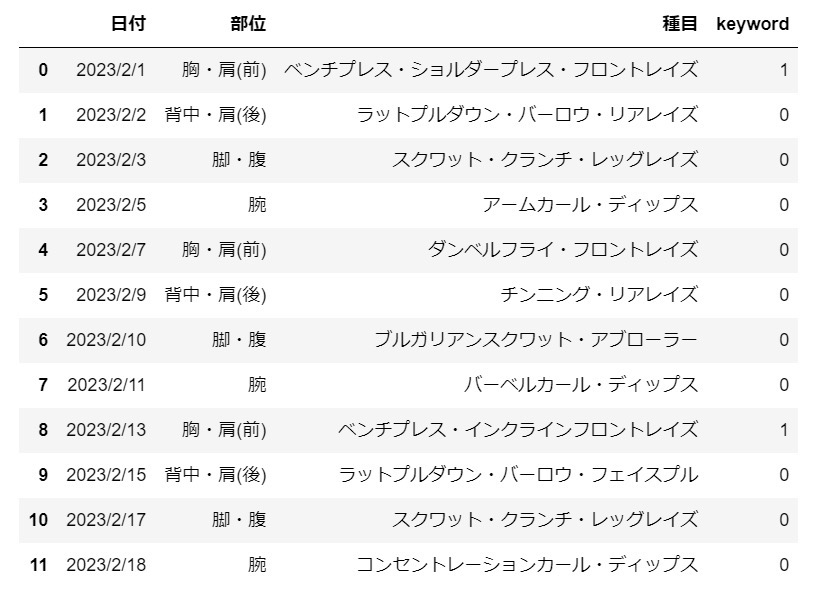
日付列のデータを日付形式に変換する
変更前のデータ形式を確認します。
df.dtypes
以下のコードを実行して日付列のデータ形式を日付形式に変換します。
df['日付'] = pd.to_datetime(df['日付'])変更後のデータ形式を確認します。
df.dtypes
日付の2023-xx-xを2023xxの形に変換する
df['日付'] = df['日付'].dt.strftime('%Y%m')
df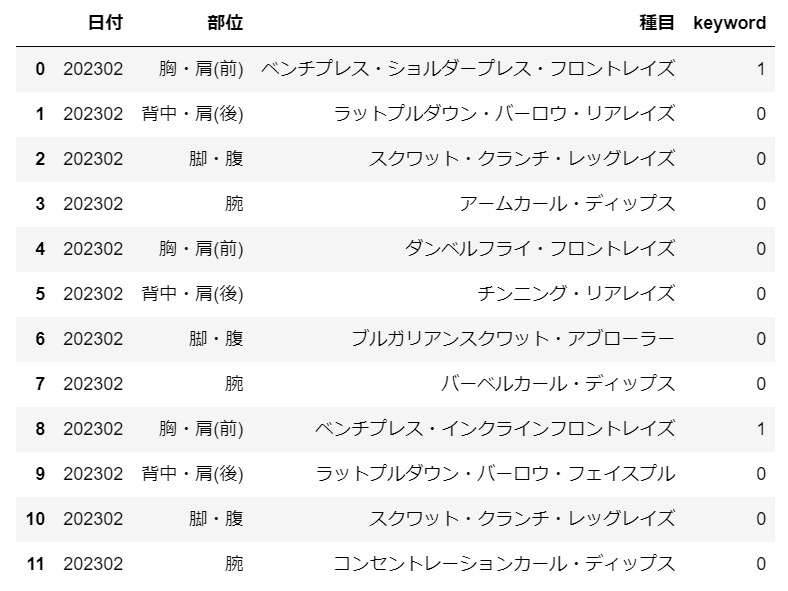
特定のワードを含む行でフィルタリングする
種目列に特定のワード(今回でいうベンチプレス)を含む場合はkeyword列に1と出力されるため、keyword列==1でフィルタリングします。
df_keyword = df[df.keyword==1]
df_keyword
同じ日付表示になっているデータをグルーピングする
df_count = df_keyword.groupby('日付').sum()
