本記事の内容
PythonのPandas、Numpyを使用して特定の列に入っているデータの文字数をカウントし、文字数ごとに集計します。
前提
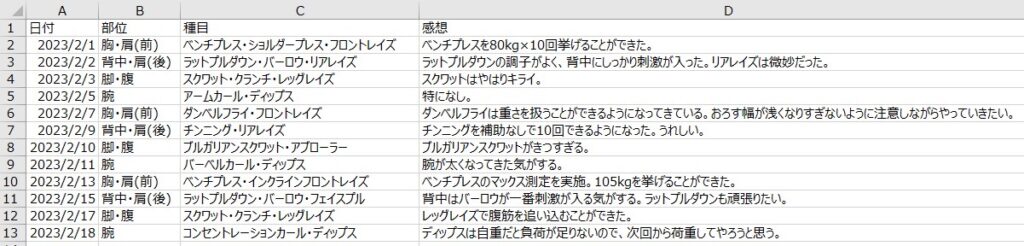
以下の画像のようなcsvファイルを使用して、本記事の内容を進めます。
ファイル名:sample.csv
Pandas、Numpyのライブラリを読み込む
import numpy as np
import pandas as pdcsvファイルを読み込む
df = pd.read_csv('sample.csv', encoding='UTF-8')
df
集計用の列を追加する
「感想」列に文字が入っている場合は1、文字が入っていない場合は0を出力する列を新たに作成します。
df['count'] = df['感想'].apply(lambda x: 1 if len(x) > 0 else 0)
df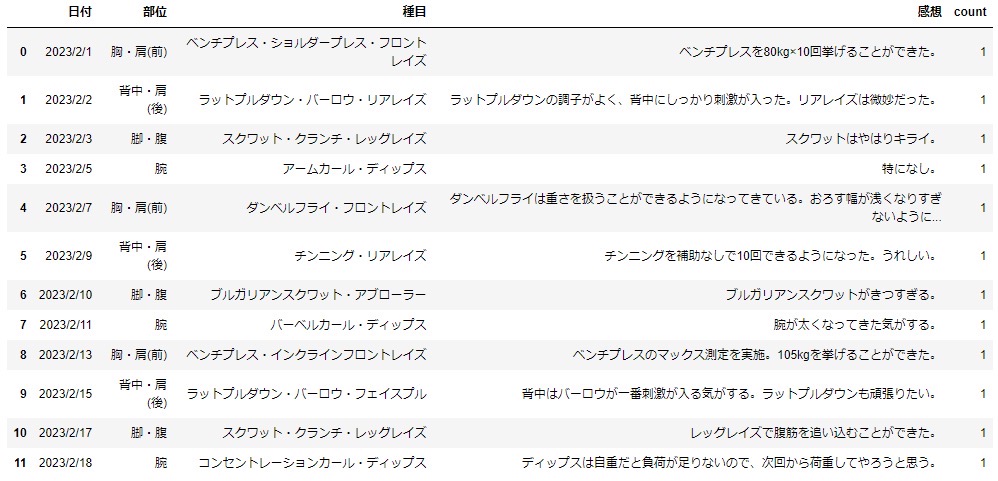
文字数を出力する列を追加する
「感想」列の各フィールドに入っている文字の長さを出力する列を作成します。
df['len'] = df['感想'].apply(lambda x: len(x))
df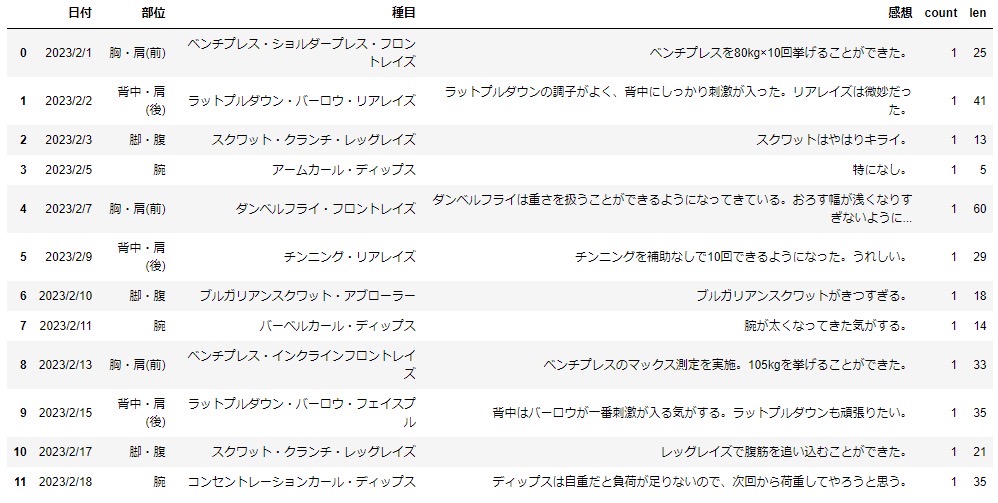
10文字区切りで集計するための列を追加する
「文字列」列の作成し、そこに文字数のカテゴリを出力します。(今回は10文字区切り)
bins = [0,10,20,30,40,50,np.inf]
labels = ['1~10','11~20','21~30','31~40','41~50','50以上']
df['文字数'] = pd.cut(df['len'], bins=bins, labels=labels)
df
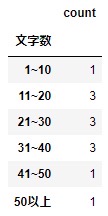
文字数のカテゴリごとに集計する
文字数のカテゴリごとに集計し、count列の合計を計算します。
文字数のカテゴリごとに、あてはまるレコードがいくつあるかがパッと見てわかるようになりました。
df_groupd = df.groupby('文字数').agg({'count':'sum'})
df_groupd